9.2 超参数优化
- 搜索空间

- 模型骨架:从小的网络到大的网络
- 学习率:
- 批量大小:
- momentum(SGD参数)
- weight decay(正则化技术)12 权重衰退
- HPO算法
- 黑盒:遍历每个超参数组合看准确率
- multi-fidelity(多置信)
- 减少数据集数量
- 减少模型大小(用更少的层数和通道数)
- 早停止(当观察到曲线不好的时候就停止训练)
- 算法详细介绍:
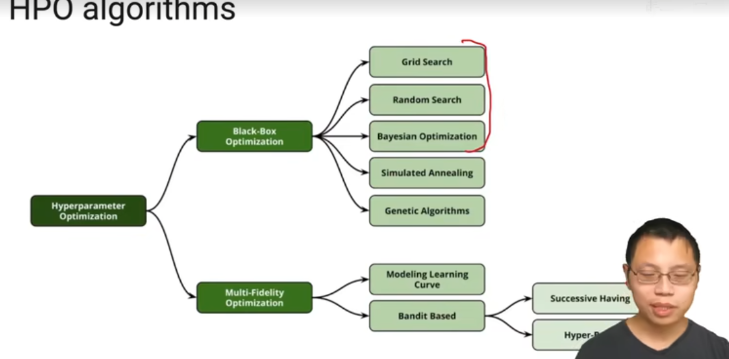
- 黑盒优化
- 梯度搜索

- 随机搜索

- 贝叶斯优化
- 梯度搜索
- 多置信优化
- successive halving:随机选n个超参数组来训练m个epoch

- hyperband:用多个SH算法重复

- successive halving:随机选n个超参数组来训练m个epoch
- 黑盒优化
- 总结
- 你可以用论文中的已知的超参数来做,意识到存在top performers